问题说明
每次Tomcat重启的时候,都会生成一个JVM崩溃的文件hs_err_pid.log和将近4G的core文件。系统正常运行时没有出现问题,只有重启的时候会有问题。下面开始排查问题。
Java Core文件生成原因
从日志文件中,可以明显看到,4G大小的core文件是因为hs_err_pid.log的产生而产生的:
hs_err_pid.log文件内容如下:
这里是正常业务日志
#
# A fatal error has been detected by the Java Runtime Environment:
#
# SIGSEGV (0xb) at pc=0x00000000000010c6, pid=2446, tid=140570273433344
#
# JRE version: Java(TM) SE Runtime Environment (8.0_66-b17) (build 1.8.0_66-b17)
# Java VM: Java HotSpot(TM) 64-Bit Server VM (25.66-b17 mixed mode linux-amd64 compressed oops)
# Problematic frame:
# C 0x00000000000010c6
#
# Core dump written. Default location: /home/....../tomcat/core or core.2446
#
# An error report file with more information is saved as:
# /home/default/tomcat/hs_err_pid2446.log
#
# If you would like to submit a bug report, please visit:
# http://bugreport.java.com/bugreport/crash.jsp
#
Java HotSpot(TM) 64-Bit Server VM warning: ignoring option MaxPermSize=128m; support was removed in 8.0
Nov 01, 2017 4:02:21 PM org.apache.catalina.core.AprLifecycleListener init
INFO: The APR based Apache Tomcat Native library which allows optimal performance in production environments was not found on the java.library.path:
这里是正常Tomcat启动的日志
起初怀疑,是操作本地so文件的时候出的错,因为我们的程序加解密的时候,会使用到自己的so文件。于是与各方排查。但是发现,只有在重启的时候才会出错,不太符合so文件的问题,否则平时也应该会时不时的发生JVM致命错误。
但是问题的根源肯定还是在与本地操作有关,因为上面hs_err_pid.log的错误信息明确的告诉我们是JNI方面的错误,问题出在C语言代码。不懂的请自行搜索hs_err_pid.log的文件内容。本地操作于是接着这个思路排查。
问题有两个:一个是与本地native操作有关,一个是只发生在重启时。所以去查看了重启时到底发生了哪些事情。
在分析的过程中意外的发现了一个问题:我们的服务器其实是做了流量切换的(流量切换是指:Tomcat重启或者发布时,新的请求会被前端的NG转发到其他机器上,避免发布时的error产生,使得发布项目如丝般顺滑),但是Tomcat在停止的前一刻,还是有请求进来了。这个时候我强烈怀疑是这个问题,因为新的请求会操作本地so文件进行加解密,而且只会发生在重启时。
带着这个猜测,我们对流量切换进行了优化,也就是增加了切换流量与实际Tomcat停止的时间间隔延长了。延长以后,流量才算真正切换成功。才不会有error产生。而此时,也再没有hs_err_pid.log和core文件产生了。
总结
这个原因导致生成hs_err_pid.log和core文件可以算是很难想到的。我们实际生产中总是会遇到各种各样的问题,需要综合各方面,全面去考虑。
附录
Java Core和Heap Dump
本节内容靠拷贝自:认识Java Core和Heap Dump
什么是Java Core和Heap Dump
Java程序运行时,有时会产生Java Core及Heap Dump文件,它一般发生于Java程序遇到致命问题的情况下。
发生致命问题后,Java进程有时可以继续运行,但有时会挂掉。
为了能够保留Java应用发生致命错误前的运行状态,JVM在死掉前产生两个文件,分别为JavaCore及HeapDump文件。
JavaCore和Heap Dump的区别
JavaCore是关于CPU的
JavaCore文件主要保存的是Java应用各线程在某一时刻的运行的位置,即JVM执行到哪一个类、哪一个方法、哪一个行上。它是一个文本文件,打开后可以看到每一个线程的执行栈,以stack trace的显示。通过对JavaCore文件的分析可以得到应用是否“卡”在某一点上,即在某一点运行的时间太长,例如数据库查询,长期得不到响应,最终导致系统崩溃等情况。
HeapDump文件是关于内存的。
HeapDump文件是一个二进制文件,它保存了某一时刻JVM堆中对象使用情况,这种文件需要相应的工具进行分析,如IBM Heap Analyzer这类工具。这类文件最重要的作用就是分析系统中是否存在内存溢出的情况。
如何生成Java Core、Heap Dump文件
这两个文件可以用手工的方式生成,当我们会遇到系统变慢或无响应的情况,这时就以采用手工的方式生成Java Core及Heap Dump文件。
在Unix/Linux上,产生这两个文件的方法如下:
# ps -ef | grep java
user 4616 4582 0 17:30 pts/0 00:00:00 grep java
root 5580 1 0 Oct27 ? 00:02:27 /usr/bin/java -server -XX:PermSize=64M -XX:MaxPermSize=128m -Djava.util.logging.manager=org.apache.juli.ClassLoaderLogManager -Djava.util.logging.config.file=/usr/local/tomcat8090/conf/logging.properties -Djava.endorsed.dirs=/usr/local/tomcat8090/endorsed -classpath :/usr/local/tomcat8090/bin/bootstrap.jar -Dcatalina.base=/usr/local/tomcat8090 -Dcatalina.home=/usr/local/tomcat8090 -Djava.io.tmpdir=/usr/local/tomcat8090/temp org.apache.catalina.startup.Bootstrap start
# kill -3 5580
首先,找出Java进程id ,然后再执行‘kill -3 进程号’的操作,等文件生成后再做一次同样的操作,再产生一组文件。
如何分析
Java Core
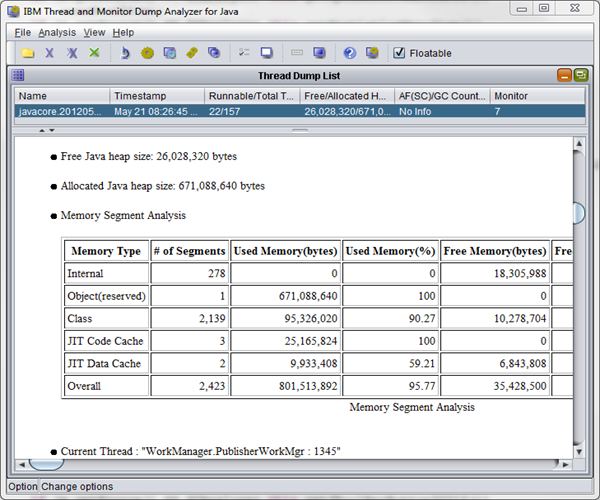
IBM Thread and Monitor Dump Analyzer for Java
功能:IBM Thread and Monitor Dump Analyzer for Java是一个可以用来分析JavaCore日志中每个线程的信息并提供诊断信息的工具。
下载后可以获得名字类似jca457.jar的文件。jca是Java Coredump Analyzer的缩写,后面的数字是版本号。
使用方法:
jca***.jar是一个可执行的jar包。可以输入以下命令来运行。
-jar是执行jar包的参数;-Xmx用来为执行jca457的进程分配最大堆内存。
java -Xmx500m -jar jca457.jar
Heap Dump
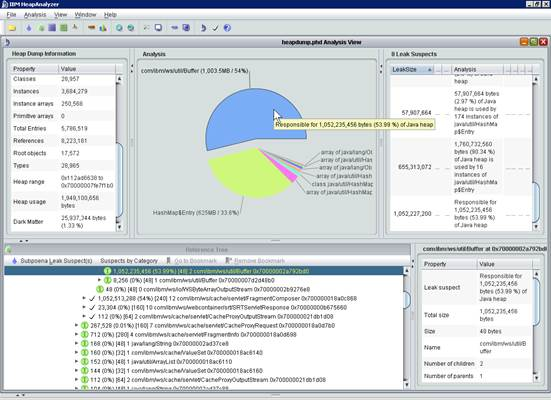
IBM HeapAnalyzer
功能:一个用来寻找Java堆缺陷的图形化工具。
下载后可以获得名字类似ha456.jar的文件。ha是Heap Analyzer的缩写,后面的数字是版本号。
使用方法:
jca***.jar是一个可执行的jar包。可以输入以下命令来运行。
-jar是执行jar包的参数;-Xmx用来为执行jca457的进程分配最大堆内存。
java –Xmx4g -jar ha456.jar
上面的代码为运行ha456的进程分配了4G的内存去运行。
注:由于发生HeapDump产生的文件往往比较大,进程在分析文件时需要占用大量内存。如果分配内存不够,有可能还没有分析完文件,程序就提示内存不够,从而中断分析。所以,必须保证你的机器的内存大小至少要大于Heap Dump文件。
参考
https://www.ibm.com/developerworks/community/groups/service/html/communityview?communityUuid=2245aa39-fa5c-4475-b891-14c205f7333c https://www.ibm.com/developerworks/community/groups/service/html/communityview?communityUuid=4544bafe-c7a2-455f-9d43-eb866ea60091 http://blog.csdn.net/newhappy2008/article/details/7592697