- 关于我的
- macApp
- 工具
- 活动资讯
- 相册
- 编写文章 ChatGpt4.0
关于我的
macApp
工具
活动资讯
相册
Java for循环嵌套for循环 性能优化
目录
前言
本篇分析的技巧点其实是比较常见的,但是最近的几次的代码评审还是发现有不少兄弟没注意到。
所以还是想拿出来说下。
正文
是个什么场景呢?
就是 for循环 里面还有 for循环, 然后做一些数据匹配、处理 这种场景。
我们结合实例代码来看看。
场景示例:
比如我们现在拿到两个list 数据 ,
一个是 User List 集合 ;
另一个是 UserMemo List集合;
我们需要遍历 User List ,然后根据 userId 从 UserMemo List 里面取出 对应这个userId 的 content 值,做数据处理。
代码 User.java :
import lombok.Data;
@Data
public class User {
private Long userId;
private String name;
}
代码 UserMemo.java :
import lombok.Data;
@Data
public class UserMemo {
private Long userId;
private String content;
}
模拟 数据集合 :
5W 条 user 数据 , 3W条 userMemo数据
public static List<User> getUserTestList() {
List<User> users = new ArrayList<>();
for (int i = 1; i <= 50000; i++) {
User user = new User();
user.setName(UUID.randomUUID().toString());
user.setUserId((long) i);
users.add(user);
}
return users;
}
public static List<UserMemo> getUserMemoTestList() {
List<UserMemo> userMemos = new ArrayList<>();
for (int i = 30000; i >= 1; i--) {
UserMemo userMemo = new UserMemo();
userMemo.setContent(UUID.randomUUID().toString());
userMemo.setUserId((long) i);
userMemos.add(userMemo);
}
return userMemos;
}
先看平时大家不注意的时候可能会这样去写代码处理 :
ps: 其实数据量小的话,其实没多大性能差别,不过我们还是需要知道一些技巧点。
代码:
public static void main(String[] args) {
List<User> userTestList = getUserTestList();
List<UserMemo> userMemoTestList = getUserMemoTestList();
StopWatch stopWatch = new StopWatch();
stopWatch.start();
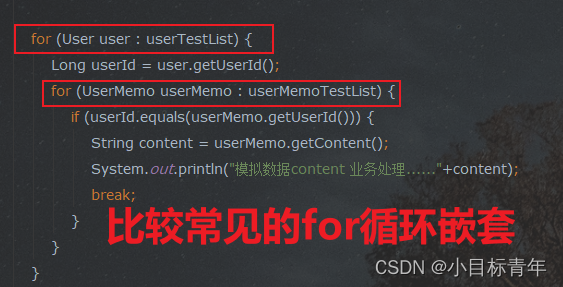
for (User user : userTestList) {
Long userId = user.getUserId();
for (UserMemo userMemo : userMemoTestList) {
if (userId.equals(userMemo.getUserId())) {
String content = userMemo.getContent();
System.out.println("模拟数据content 业务处理......"+content);
}
}
}
stopWatch.stop();
System.out.println("最终耗时"+stopWatch.getTotalTimeMillis());
}
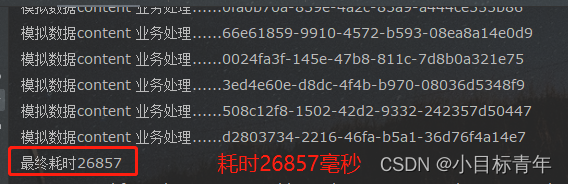
我们来看看 这时候的一个耗时情况 :
相当于迭代了 5W * 3W 次
可以看到用时 是 26857毫秒
其实到这,插入个题外点,如果说每个userId 在 UserMemo List 里面 都是只有一条数据的场景。
for (User user : userTestList) {
Long userId = user.getUserId();
for (UserMemo userMemo : userMemoTestList) {
if (userId.equals(userMemo.getUserId())) {
String content = userMemo.getContent();
System.out.println("模拟数据content 业务处理......"+content);
}
}
}
单从这段代码有没有问题 ,有没有优化点。
显然是有的, 因为当我们从内循环UserMemo List里面找到匹配数据的时候, 没有做其他操作了。
这样 内for循环会继续下,直到跑完再进行下一轮整体循环。
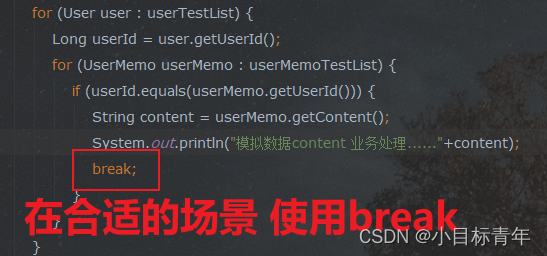
所以,仅针对这种情形,1对1的或者说我们只需要找到一个匹配项,处理完后我们 应该使用 break 。
我们来看看 加上 break 的一个耗时情况 :
代码:
public static void main(String[] args) {
List<User> userTestList = getUserTestList();
List<UserMemo> userMemoTestList = getUserMemoTestList();
StopWatch stopWatch = new StopWatch();
stopWatch.start();
for (User user : userTestList) {
Long userId = user.getUserId();
for (UserMemo userMemo : userMemoTestList) {
if (userId.equals(userMemo.getUserId())) {
String content = userMemo.getContent();
System.out.println("模拟数据content 业务处理......"+content);
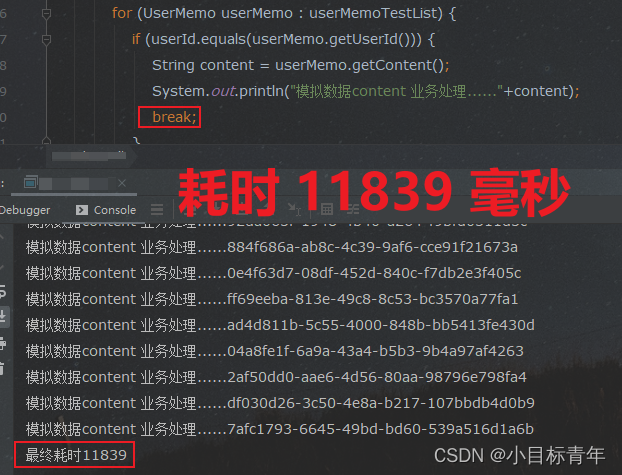
break;
}
}
}
stopWatch.stop();
System.out.println("最终耗时"+stopWatch.getTotalTimeMillis());
}
耗时情况:
可以看到 从 2W 多毫秒 变成了 1W 多毫秒, 这个break 加的很OK。
<hr>
回到我们刚才, 平时需要for 循环 里面再 for 循环 这种方式,可以看到耗时是 2万6千多毫秒。
那如果场景更复杂一定, 是for 循环里面 for循环 多个或者, for循环里面还有一层for 循环 ,那这样代码耗时真的非常恐怖。
那么接下来这个技巧点是 使用map 去优化 :
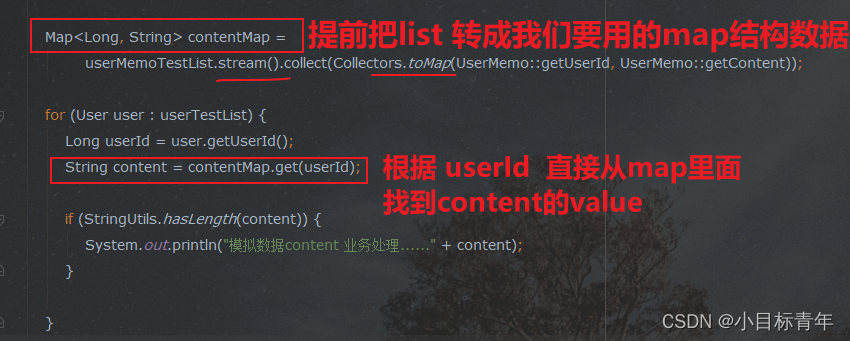
代码:
public static void main(String[] args) {
List<User> userTestList = getUserTestList();
List<UserMemo> userMemoTestList = getUserMemoTestList();
StopWatch stopWatch = new StopWatch();
stopWatch.start();
//使用stream() 记得一定要判空 这里没列出来,大家自己注意
Map<Long, String> contentMap =
userMemoTestList.stream().collect(Collectors.toMap(UserMemo::getUserId, UserMemo::getContent));
for (User user : userTestList) {
Long userId = user.getUserId();
String content = contentMap.get(userId);
if (StringUtils.hasLength(content)) {
System.out.println("模拟数据content 业务处理......" + content);
}
}
stopWatch.stop();
System.out.println("最终耗时" + stopWatch.getTotalTimeMillis());
}
看看耗时:
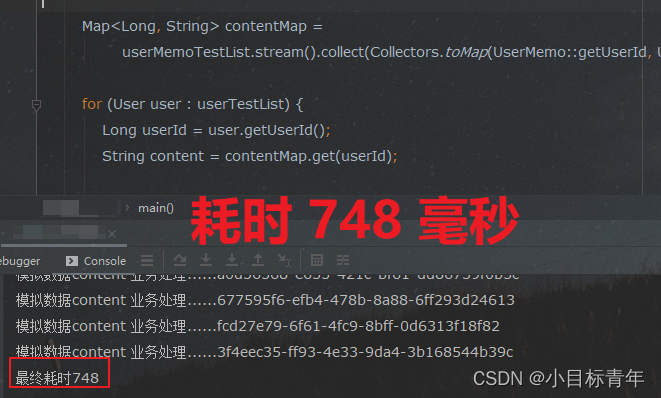
为什么 这么显著的效果 ?
这其实就是时间复杂度,
for循环嵌套for循环,
就好比 循环每一个 user ,拿出 userId
需要在里面的循环从 userMemo list集合里面 按顺序去开盲盒匹配,
拿出第一个,看看userId ,拿出第二个,看看userId ,一直找匹配的。
而我们提前对 userMemo list集合 做一次 遍历,转存储在map里面 。
map的取值效率 在多数的情况下是能维持接近 O(1) 的 , 毕竟数据结构摆着,数组加链表。
相当于拿到userId 想去开盲盒的时候, 根据userId 这个key hash完能直接找到数组里面的索引标记位, 如果底下没链表(有的话O(logN)),直接取出来就完事了。
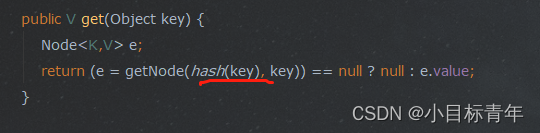
然后补充一个getNode的代码注释 :
/**
* Implements Map.get and related methods.
* 这是个 Map.get 的实现 方法
* @param hash hash for key
* @param key the key
* @return the node, or null if none
*/
// final 写死了 无法更改 返回 Node 传入查找的 hash 值 和 key键
final Node<K,V> getNode(int hash, Object key) {
// tab 还是 哈希表
// first 哈希表找的链表红黑树对应的 头结点
// e 代表当前节点
// k 代表当前的 key
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
// 赋值 并过滤 哈希表 空的长度不够的 对应位置没存数据的 都直接 return null
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
// 头结点就 找到了 hash相等值相等 或者 不空的 key 和当前节点 equals
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first;
// 头结点不匹配 没找到就 就用 next 找
if ((e = first.next) != null) {
// 是不是红黑树 的
if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
// 红黑树就直接 调用 红黑树内查找
// 不为空或者没找到就do while 循环
do {
// 当前节点 找到了 hash相等值相等 或者 不空的 key 和当前节点 equals
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}
=
按照目前以JDK8 的hash算法,起hash冲突的情况是非常非常少见了。 最恶劣的情况,只有当 全部key 都冲突, 全都分配到一个桶里面去都占用一个位置 ,这时候就是O(n),这种情景不需要去考虑。
好了,该篇就到这。
本文章网址:https://www.sjxi.cn/detil/0b8704ed36334e0f851b1f6b168cd32e
打赏作者
本站为非盈利网站,如果您喜欢这篇文章,欢迎支持我们继续运营!
推荐阅读
最新评论
当前未登陆哦
登陆后才可评论哦关于此站
本站主要用于日常笔记的记录和生活日志。本站不保证所有内容信息可靠!(大多数文章属于搬运!)如有版权问题,请联系我立即删除:“abcdsjx@126.com”。
学习网站
优秀排版个人博客
×
(穷逼博主)在线接单
QQ: 1164453243
邮箱: abcdsjx@126.com
前端项目代做
前后端分离
Python 爬虫脚本
Java 后台开发
各种脚本编写
服务器搭建
个人博客搭建
Web 应用开发
Chrome 插件编写
Bug 修复